Notes from reading MapReduce: Simplified Data Processing on Large Clusters (MapReduce: Simplified Data Processing on Large Clusters - Jeffrey Dean and Sanjay Ghemawat). Below: the abstraction and why it exists, the execution flow, and how the runtime handles partitioning, workers, and failures.
Abstract
- Used for processing and generating large data sets
- user specifies a map and reduce functions which are automatically parallelized and executed on a large cluster of commodity machines
Introduction
Engineers @Google have implemented hundreds of special-purpose computations that process large amounts of raw data.
- crawled documents.
- web request logs
In order to compute various kinds of derived data
- inverted indices
- graph structure of web documents
- summaries of the number of pages crawled per host
- the set of most frequent queries in a given day
The issues of how to parallelize the computation, distribute the data, and handle failures conspire to obscure the original simple computation with large amounts of complex code to deal with these issues.
- as a result of the complexity, an abstraction that allows engineers to express the simple computations they want to perform by hiding parallelization, fault-tolerance, data distribution, and load balancing
- most of the computations involved applying applying a map operation to each logical “record” in the input in order to compute a set of intermediate key/value pairs, an then perform a reduce operation to all the values that shared the same key, in order to combine the derived data appropriately
Programming model
- Map, written by the user, takes an input pair and produces a set of intermediate key/value pairs. The MapReduce library groups together all intermediate values, associated with the same intermediate key and passes them to the reduce function
- Reduce, written by the user, accepts an intermediate key and a set values for that key. It merges together those values to form a possibly smaller set of values. Typically just zero or one output value is produced per Reduce invocation. The intermediate values are supplied user’s function via an iterator. This allows us to handle lists of values that are too large to fit in memory.
Example:
Count number of occurrences of each word in a large collection of documents
map(String key, String val):
// key - document name
// val - document contents
for w in val:
EmitIntermediate(w, "1")
reduce(key,val):
// key - a word
// val - a list of counts
int result = 0
for v in val:
result += ParseInt(v)
Emit(AsString(result))
More use cases of MapReduce
- Distributed Grep
- Count of URL access frequency
- Reverse Web-Link Graph
- Term-Vector per host
- Inverted Index
- Distributed Sort
Implementation
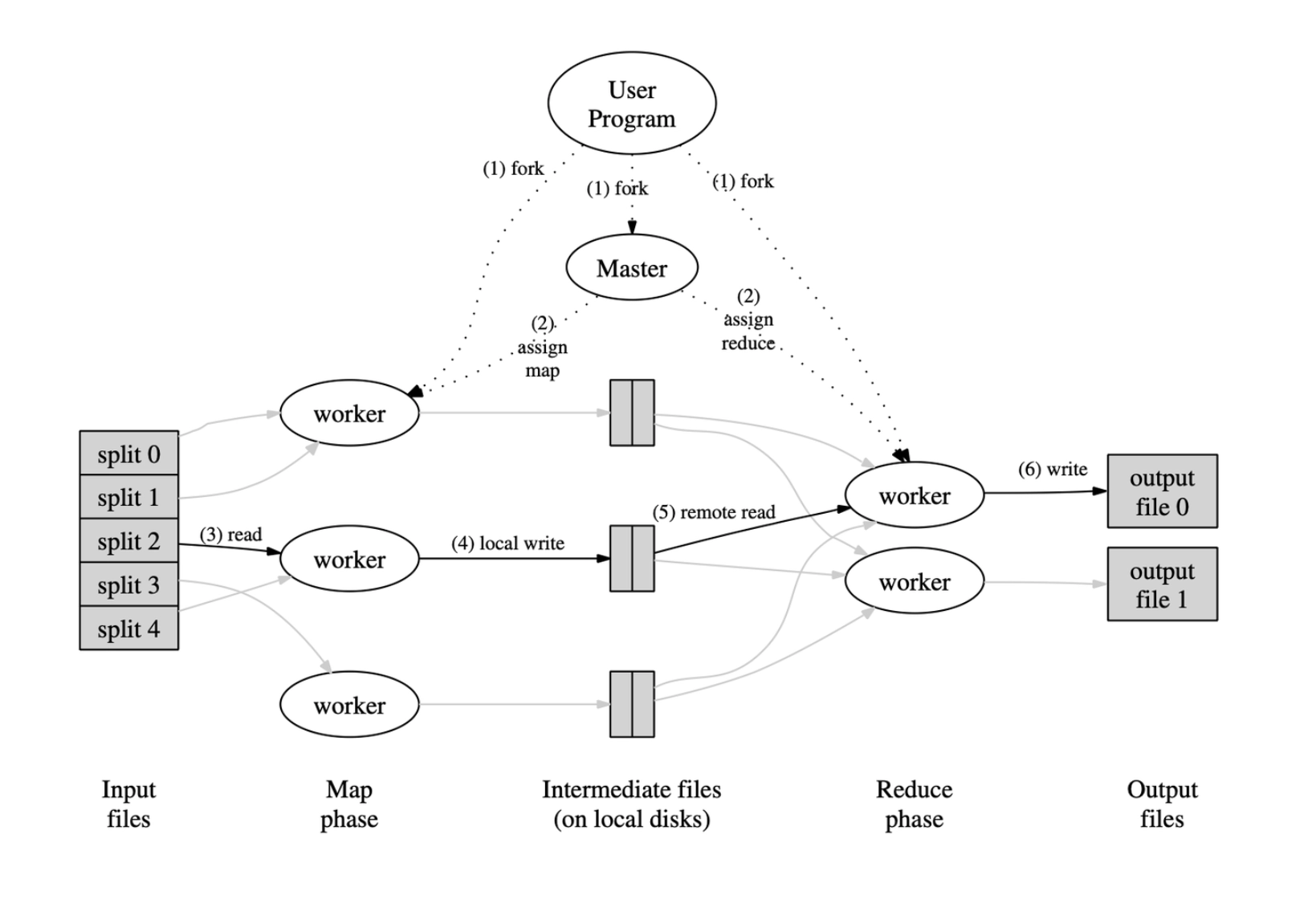
Figure: Overview of MapReduce Execution Flow
This diagram illustrates the major components and data flow in a typical MapReduce job:
- Input files are split into chunks (split 0, split 1, …, split 4), each processed by a separate map worker.
- The map phase distributes splits to workers, with each worker reading its assigned split and writing intermediate key-value pairs to local disk.
- Intermediate files are partitioned and stored locally by each map worker.
- The reduce phase starts when reduce workers remotely read the relevant intermediate files, sort and group them by key, and run the user-defined reduce function on each group.
- The final output from reduce workers is written into one or more output files.
The master node coordinates the entire process, handling worker assignment and tracking completion.
This corresponds directly to the steps enumerated below the diagram and is central to the design described in the original MapReduce whitepaper.
- The MapReduce Library in the user program splits the input files into pieces of typically 16 to 64MB per piece
- Master assigns work to idle map/reduce workers
- A worker who is assigned a map task reads the contents of the corresponding split, parses the input, and passes each key/value pair to the user-defined Map. The intermediate key/value pairs are buffered in memory
- Periodically the buffered pairs are written to local disk, partitioned into R regions by the partitioning function. Locations are passed to the master
- When a reduce worker is notified by the master about the locations of the intermediate files it uses RPC calls to read the buffered data from the local disks of the map workers. When a reduce worker has read all intermediate data, it sorts it by the intermediate keys, so that all key occurrences are grouped together. The sorting is needed because typically many different keys map to the same reduce task. If the amount of intermediate data is too large to fit in memory an extern sort is used.
- The reduce work iterates over the sorted intermediate data, and for each intermediate unique key, it passes the key, and the corresponding set of intermediate values to the user’s Reduce function. The output of the Reduce function is appended to a final output file for this reduce partition.
- When all map reduce tasks have been completed, the master wakes the user program